Ở bài viết Đánh giá tính phân biệt thang đo bằng bảng Fornell and Larcker, chúng ta đã làm quen với một cách đánh giá giá trị phân biệt giữa các thang đo (tập chỉ báo). Henseler và cộng sự (2015) đã đưa ra những bằng chứng thuyết phục rằng cách phương pháp của Fornell và Larcker (1981) đề xuất sẽ không thực sự đánh giá được tính phân biệt của một thang đo. Từ đó, nhóm tác giả này đã đề xuất một phương pháp đánh giá thay thế và được chấp nhận rộng rãi trong giới nghiên cứu, gọi là chỉ số tương quan Heterotrait-Monotrait (Heterotrait-Monotrait Ratio of Correlations), viết tắt là HTMT.

1. Lý thuyết hình thành cách tính chỉ số HTMT
Chỉ số HTMT được tính toán dựa trên nền tảng ma trận multitrait-multimethod (MTMM) do Campbell và Fiske (1959) đề xuất. Ma trận này yêu cầu có ít nhất hai tập chỉ báo để đo lường cho hai biến tiềm ẩn khác nhau (multiple traits) và mỗi tập chi báo có số lượng bằng nhau (ma trận cân bằng - symmetric matrix). Ma trận vừa nêu đơn giản chính là ma trận tương quan giữa các chi báo của các biển biến tiềm ẩn. Trước khi đi vào công thức tính toán chỉ số HTMT, chúng ta sẽ hình dung qua ma trận MTMM của hai khái niệm A và B được mô tả tại hình bên dưới để hiểu được lý thuyết cơ sở của chỉ số HTMT.
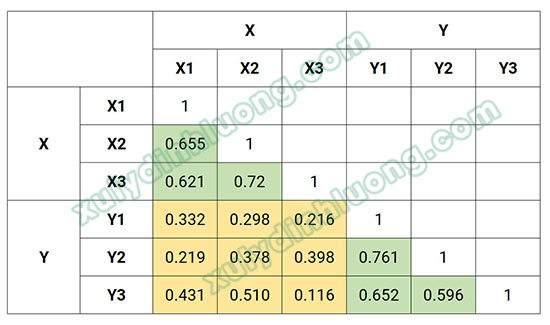
Bảng trên minh họa ma trận tương quan giữa sáu chỉ báo đo lường cho hai biến tiệm ẩn X và Y. Các hệ số tương quan trong ma trận tương quan này được chia thành ba phần và được tô màu 2 xanh - 1 vàng.
Các hệ số tương quan trong phần tô xanh là tương quan nội bộ (inter-item correlation) giữa các chỉ báo đo lường cùng một biến tiềm ẩn và được đặt tên là "monotraitheteromethod correlations”. Hệ số tương quan nằm trong phần tô vàng chính là hệ số tương quan chéo giữa các chỉ báo của cả hai biến tiềm ẩn và được đặt tên là "heterotrait-heteromethod correlations".
2. Đánh giá tính phân biệt qua chỉ số HTMT
Cơ sở đánh giá tính phân biệt sẽ dựa trên ý tưởng: Hệ số tương quan trung bình trong nội bộ một thang đo càng lớn hơn trung bình các hệ số tương quan chéo càng tốt. Khi hệ số tương quan trung bình trong nội bộ một thang đo càng cao, biển tiềm ẩn chia sẻ sự biến động càng lớn trong nội bộ của thang đo đó. Nếu trung bình của các hệ số tương quan chéo càng thấp chứng tỏ biến tiềm ẩn vừa nêu càng ít chia sẻ sự biến động tới biển tiềm ẩn khác. Khi đó, các chỉ báo ở hai biến tiềm ẩn sẽ đạt được giá trị phân biệt.
Xuất phát từ nhận định trên, Henseler và cộng sự (2015) đưa ra công thức đánh giá giá trị phân biệt bằng HTMT theo từng cặp thang đo như sau:
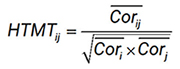
Trong đó:
- HTMTij: giá trị HTMT của cặp biến tiềm ẩn i và j
- Corij: trung bình cộng hệ số tương quan tất cả các cặp biến quan sát của biến tiềm ẩn i và j
- Cori :trung bình cộng hệ số tương quan các cặp biến quan sát của biến tiềm ẩn i
- Corj :trung bình cộng hệ số tương quan các cặp biến quan sát của biến tiềm ẩn j
Để dễ hiểu hơn, chúng ta sẽ tính HTMT cặp biến X-Y trong ví dụ đề cập ở bảng bên trên.
- CorXY = (0.332 + 0.298 + 0.216 + 0.219 + 0.378 + 0.398 + 0.431 + 0.510 + 0.116) / 9 = 0.322
- CorX = (0.655 + 0.621 + 0.720) / 3 = 0.666
- CorX = (0.761 + 0.652 + 0.596) / 3 = 0.670
Gắn các chỉ số này vào công thức tính HTMT, chúng ta có như sau:

Như vậy, trung bình hệ số tương quan chéo monotrait-heteromethod giữa các chỉ báo của cả hai biến tiềm ẩn X và Y phải càng nhỏ hơn trung bình nhân hệ số tương quan monotrait-heteromethod của X và Y càng tốt. Khi đó, hai biến tiềm ẩn X và Y chủ yếu chia sẻ sự biến động cho các chỉ báo trong nội bộ của mỗi thang đo mà ít chia sẻ sự biến động cho nhau. Lúc này, tập hợp các chỉ báo của biến tiềm ẩn X sẽ đảm bảo tính phân biệt với tập hợp các chỉ báo của biển tiềm ẩn Y.
Henseler và cộng sự (2015) đưa ra đề xuất về hai ngưỡng đánh giá giá trị phân biệt giữa tập chỉ báo của biến tiềm ẩn i và của biến tiềm ẩn j như sau:
- Nếu HTMTij > 0.9, khó đạt được giá trị phân biệt giữa hai biến tiềm ẩn i và j. Có nghĩa là dữ liệu của tập chỉ báo i và j khá tương đồng nhau.
- Nếu HTMTij ≤ 0.85, đạt được giá trị phân biệt giữa hai biến tiềm ẩn i và j.
Theo tính toán từ ví dụ bên trên, chỉ số HTMTXY = 0.482 ≤ 0.85 nên có thể kết luận X và Y đảm bảo tính phân biệt với nhau. Nếu mô hình nghiên cứu có thêm các biến tiềm ẩn M, N (đều là dạng mô hình kết quả reflective), chúng ta sẽ xét chỉ số HTMT theo từng cặp X-Y, X-M, X-N, Y-M, Y-N, M-N.
3. Đọc kết quả bảng HTMT trên SMARTPLS 3, 4
Tuy giao diện output SMARTPLS 3 và SMARTPLS 4 có nhiều điểm khác biệt nhưng giá trị HTMT sẽ luôn nằm trong kết quả phân tích PLS Algorithm. Ngưỡng HTMT phù hợp sẽ là từ 0.9 trở xuống.
- Nếu giá trị HTMT của một cặp biến dưới 0.85, SMARTPLS sẽ hiển thị màu xanh (rất tốt);
- Nếu giá trị HTMT của một cặp biến từ 0.85 đến 0.9, SMARTPLS sẽ hiển thị màu đen (chấp nhận);
- Nếu giá trị HTMT của một cặp biến lớn hơn 0.9, SMARTPLS sẽ hiển thị màu đỏ (vi phạm);
Để xem bảng HTMT trên SMARTPLS 3, chúng ta chạy PLS Algorithm, nhấp vào mục Discriminant Validity.

Sau đó chọn vào thẻ thứ ba: Heterotrait-Monotrait Ratio (HTMT).

→ Kết quả từ ví dụ thực hành cho thấy toàn bộ giá trị HTMT đều nhỏ hơn 0.9, như vậy tính phân biệt được đảm bảo.
Để xem kết quả bảng HTMT trên SMARTPLS 4, từ kết quả phân tích PLS-SEM algorithm, nhấp vào mục Discriminant validity, chọn Heterotrait-monotrait ratio (HTMT) - Matrix.

→ Kết quả từ ví dụ thực hành cho thấy toàn bộ giá trị HTMT đều nhỏ hơn 0.9, như vậy tính phân biệt được đảm bảo (dữ liệu của kết quả minh họa ở 2 phiên bản SMARTPLS 3,4 ở trên là khác nhau, nếu cùng một bộ dữ liệu thì kết quả HTMT ở các phiên bản đều như nhau).
Xem thêm: Đánh giá tính phân biệt thang đo bằng bảng Fornell and Larcker
Xem thêm: Đánh giá tính phân biệt qua bảng Cross-Loading trong SMARTPLS