Trong phân tích nhân tố khám phá EFA bằng phần mềm SPSS, hai tiêu chuẩn trích được sử dụng để xác định số lượng nhân tố cần giữ lại là dựa vào hệ số Eigenvalue lớn hơn 1 (Extract Based on Eigenvalue > 1) và Trích cố định số nhân tố mong muốn (Fixed Number of Factors). Cả hai có ưu và nhược điểm riêng, phụ thuộc vào mục tiêu nghiên cứu và dữ liệu.

Trong tùy chọn Extraction của EFA trên SPSS, phần Extract sẽ có giao diện hiển thị hai tiêu chuẩn trích như ảnh bên dưới.

1. Hệ số Eigenvalue lớn hơn 1 (Extract Based on Eigenvalue > 1)
Hair và cộng sự (2009) cho rằng chỉ những nhân tố có hệ số eigenvalue (hay còn gọi là latent roots) trên 1 mới được đánh giá là có ý nghĩa và được giữ lại.
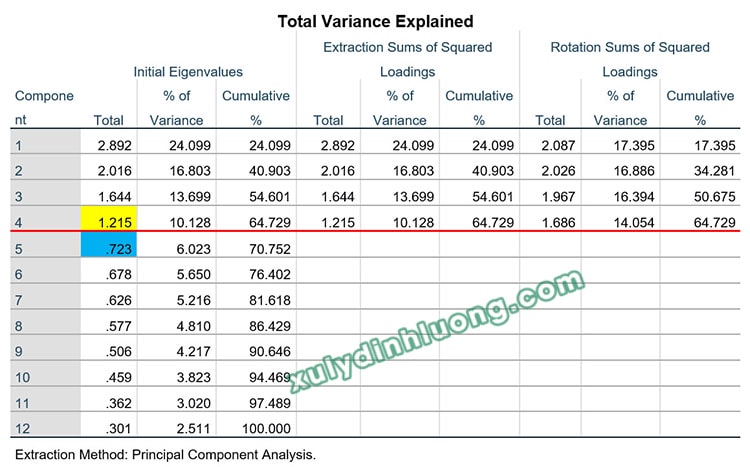
Hệ số Eigenvalue trên SPSS sẽ nằm trong bảng Total Variance Explained. Cột Component luôn bằng với số lượng biến quan sát tham gia vào EFA. Cột Initial Eigenvalues biểu diễn giá trị eigenvalue ban đầu khi quá trình trích nhân tố chưa diễn ra. Ở cột Component có bao nhiêu nhân tố thì cột Initial Eigenvalues sẽ cung cấp giá trị tương ứng của toàn bộ các nhân tố này. Cột Extraction Sums of Squared Loadings là kết quả khi đã kết thúc quá trình trích nhân tố.
Trong ví dụ ở trên, từ 12 biến quan sát ban đầu, kết thúc quá trình trích thu được 4 nhân tố. Cột Rotation Sums of Squared Loadings đưa ra kết quả các chỉ số sau khi kết thúc quá trình xoay nhân tố. Kết quả ở bảng trên cho thấy, giá trị eigenvalue tại nhân tố thứ 4 là 1.215 > 1, tại nhân tố thứ 5 là 0.723 < 1. Dựa theo tiêu chí eigenvalue > 1, quá trình trích sẽ dừng tại nhân tố thứ 4, có 4 nhân tố được trích.
Tóm lại với tiêu chuẩn trích hệ số Eigenvalue > 1:
Cách hoạt động:
- Giữ lại các nhân tố có giá trị riêng (eigenvalue) lớn hơn 1.
- Giá trị riêng thể hiện lượng biến thiên của dữ liệu được giải thích bởi một nhân tố.
Ưu điểm:
- Đơn giản và tự động, không cần quyết định trước số lượng nhân tố.
- Thường là lựa chọn mặc định trong SPSS và các phần mềm phân tích EFA khác.
Nhược điểm:
- Có thể giữ lại quá nhiều nhân tố khi dữ liệu có nhiều biến nhiễu.
- Khi số lượng biến quá lớn, phương pháp này có thể không chính xác vì có thể giữ lại các nhân tố không thực sự ý nghĩa.
Ứng dụng:
Phù hợp trong trường hợp chưa có cơ sở lý thuyết rõ ràng về số lượng nhân tố. Là tiêu chuẩn trích sử dụng phổ biến vì trích nhân tố theo bản chất của dữ liệu gốc.
2. Chọn số nhân tố kỳ vọng (Fixed Number of Factors)
Khi nghiên cứu có lý thuyết nền rất mạnh chỉ ra rằng với đề tài nghiên cứu này, chỉ có một số lượng nhân tố cố định được trích, chúng ta có thể dùng tới phương pháp xác định số nhân tố kỳ vọng bằng cách bắt buộc phần mềm chỉ trích ra số lượng nhân tố theo yêu cầu.
Theo Hair và cộng sự (2009), hướng tiếp cận của phương pháp này rất hữu ích trong việc kiểm tra lý thuyết nghiên cứu hoặc giả thuyết về số nhân tố được trích khi chúng ta thực hiện các nghiên cứu lặp lại. Nghĩa là vấn đề nghiên cứu đã được nhiều nhà nghiên cứu trước đó thực hiện, chúng ta chỉ thay đổi về môi trường khảo sát hoặc một số điều chỉnh nhỏ (các điều chỉnh không thay đổi cấu trúc thang đo và mô hình lý thuyết), việc sử dụng phương pháp này là một hướng đi tốt để đạt được cấu trúc nhân tố phù hợp.

Tóm lại với tiêu chuẩn trích Fixed Number of Factors:
Cách hoạt động:
Người dùng quy định trước số lượng nhân tố cần giữ lại, dựa trên lý thuyết hoặc giả thuyết nghiên cứu.
Ưu điểm:
- Giảm nguy cơ giữ lại các nhân tố không quan trọng.
- Dễ kiểm soát số lượng nhân tố nếu có lý thuyết hoặc bằng chứng thực nghiệm hỗ trợ.
Nhược điểm:
- Phụ thuộc nhiều vào quyết định chủ quan của người nghiên cứu.
- Có thể bỏ qua các nhân tố thực sự quan trọng nếu số lượng nhân tố cố định không chính xác.
Ứng dụng:
Phù hợp khi nghiên cứu đã có lý thuyết nền tảng hoặc dự kiến trước số lượng nhân tố hoặc khi nhà nghiên cứu muốn thử nghiệm chất lượng dữ liệu có phù hợp với cơ sở lý thuyết không.
Trong làm đề tài nghiên cứu, luận văn bạn thực sự cân nhắc tiêu chuẩn trích này bởi vì cơ chế hoạt động chủ quan theo ý muốn của cá nhân của nhà nghiên cứu sẽ gây ra tranh cãi vì đi không đúng với bản chất của dữ liệu.
Kết luận
Extract Based on Eigenvalue > 1 phù hợp nếu bạn muốn tự động khám phá cấu trúc dữ liệu mà không có giả định cụ thể về số lượng nhân tố.
Fixed Number of Factors lý tưởng hơn khi có lý thuyết hỗ trợ hoặc mục tiêu nghiên cứu rõ ràng về số lượng nhân tố.